摘要:
為了觀察學生在線上學習中的實際成效,我們蒐集了110-112學年創課中對於學生觀看影片的34項特徵數值共9629筆學生數據,並配合機器學習的各種模型進行分析預測,建立學生及格與否的預測模型。透過不同學習法的比較與驗證,找出最佳模型以提升預測準確率。 我們在實驗中參考了6種機器學習模型以及3種組合融合技術對於現有的數據進行訓練並記錄,將最佳模型及預測結果儲存為.pgz格式同時將每個split下的預測結果存置存至csv檔。因為模型訓練的參數配置有許多搭配方式,利用格網搜尋(Grid Search)的方式能遍歷參數字典中的所有組合,盡可能的求得目前的最佳預測參數配置,並結合交叉驗證將各項指標紀錄計算95%信賴區間(Confidence Interval, CI)用來衡量指標的穩定性。
研究方法:
在機器學習部分,針對110-112 學年「創課」課程中學生觀看影片的數據,經過清洗並移除無關欄位(如:學年、學期等)後,所選取的特徵欄位如圖一所示。由於資料集存在類別不平衡的問題,及格類別佔據絕大多數比例,而未及格類別僅佔 6.76%,這樣的分布可能會導致模型過度偏向多數類別,忽略少數類別的辨識能力。因此,在最佳模型的評估上,我們主要關注特異度 (Specificity) 和準確度 (Accuracy)。特異度的公式如圖二所示,主要用於計算模型對「負類別 (未及格)」的辨識能力,能顯著反映出模型在類別不平衡下對少數類別的識別效果,避免模型過度傾向預測多數類別,出現即使全部預測為及格也能達到高準確率(93.24%)的情況。而準確度則綜合考量模型對正類別與負類別的預測結果,能有效評價模型整體的分類效果,同時也是我們主要追求的目標數值。在模型訓練設計中,我們透過參數網格 (Parameter Grid) 設置超參數組合,並使用格網搜尋 (Grid Search) 遍歷字典中的所有參數組合,確保在多組參數中找到最佳配置,進而提升模型的預測能力。具體步驟如下:首先,使用train_test_split() 將數據隨機分為80% 訓練集和20% 測試集,並重複進行30 次迭代分割,確保模型結果的穩定性;其次,對每次資料分割,遍歷各模型的參數組合(包括penalty、C、solver、max_iter 等參數),訓練模型並計算其在測試集上的準確度和特異度,若模型表現超過當前最佳結果,則更新為最佳模型,並保存相應的參數組合與預測結果;接著,使用pickle 將表現最佳的模型保存為 .pgz 壓縮檔案,並將預測結果輸出為 CSV 文件。最後,根據混淆矩陣計算模型的特異度、靈敏度、F1 分數、AUC-ROC 等評估指標,並計算95% 信賴區間 來量化各指標的穩定性,進一步驗證模型在類別不平衡情境下的預測表現。
在組合學習技術部分,程式使用 VotingClassifier 集成多個基學習器,包括Random Forest、Gradient Boosting、XGBoost、LightGBM 和 CatBoost 等模型,同樣設計了網格搜尋,對每個基模型的參數進行組合測試,以尋找最佳的超參數組合。在每次迭代中,程式進行30 次重複隨機分割,將資料集分為訓練集和測試集,針對每個參數組合訓練模型計算性能指標並紀錄,包括準確率 (Accuracy)、靈敏度 (Sensitivity)、特異度 (Specificity)、F1 分數 (F1-Score) 和 AUC-ROC。程式特別加入閾值調整機制,以不同的閾值對模型預測結果進行調整,計算負類別精確率 (Precision N) 和負類別 F1 分數 (F1 N),並根據這兩個指標進行最佳化,找出在少數類別識別上表現最佳的模型和參數。 在MLP模型部分,程式使用 PyTorch 建立多層感知器 (MLP) 神經網絡模型來進行分類任務,並結合資料預處理、平衡技術 (SMOTEENN)、模型訓練與性能評估。
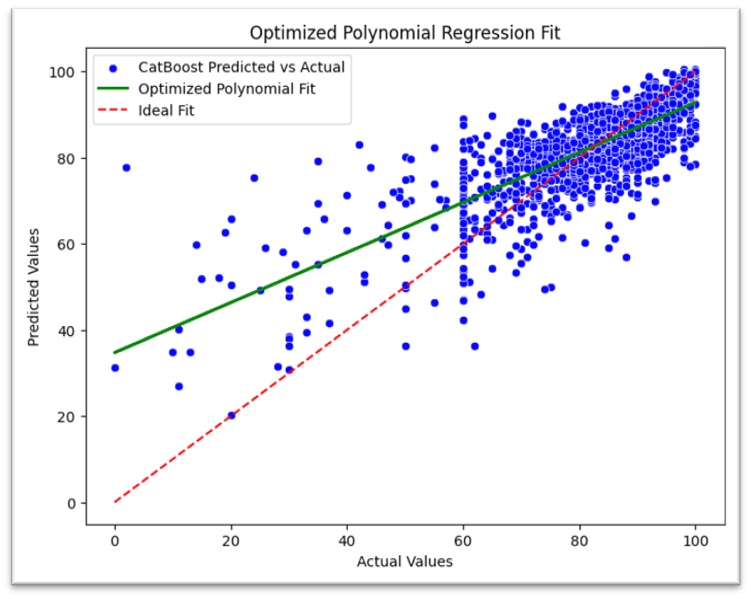
在迴歸模型部分,程式同樣設計了網格搜尋與隨機搜索機制,模型採用了 Random Forest、Gradient Boosting、SVR和AdaBoost等模型,同樣設計了網格搜尋,對每個基模型的參數進行組合測試。在效能評估上使用散點圖繪製出實際值與預測值的比較,並搭配殘差分析,同時也對迴歸模模型嘗試設置分數閥值,將連續數值轉換為二元分類並計算混淆矩陣及相關性能指標。
結論:
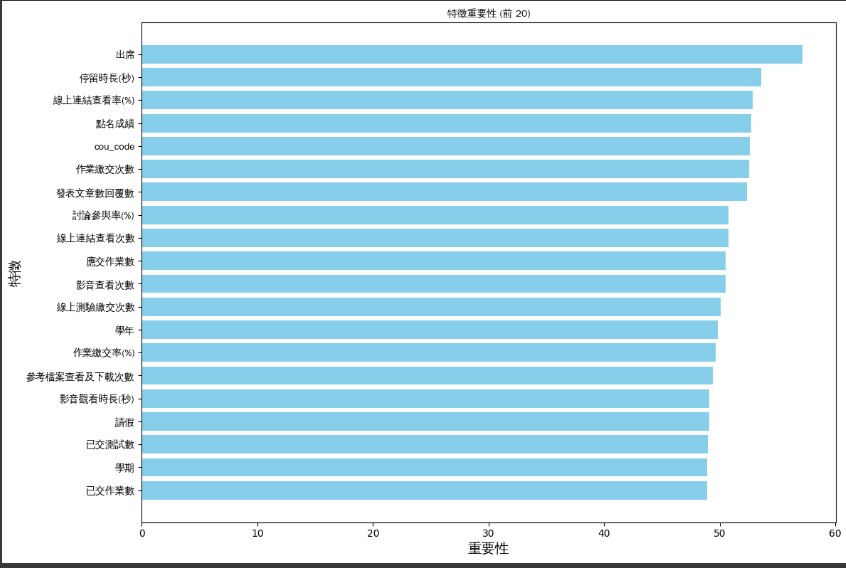
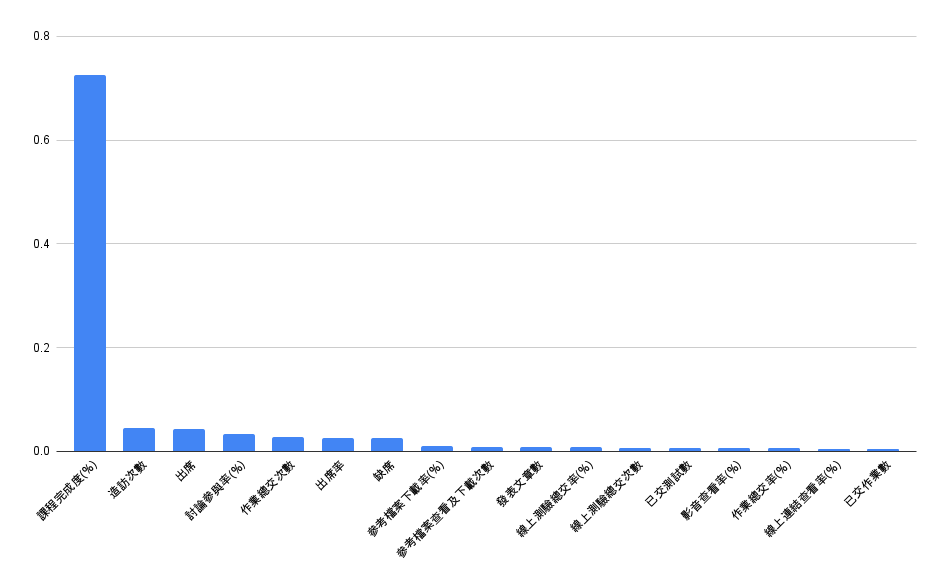
基於上述幾種訓練後的模型進行特徵權重分析,我們能做出兩種層面的判斷。第一種基於教育層面,能看出機器學習對於特徵的選取主要看中課程完程度(%),而在MLP模型的部分則是每部分的特徵值都有不錯的重要性,其中前三高的特徵欄位,出席、停留時長(秒)、線上連結查看率(%)都主要體現在學生對於課程的參與度影響學生成績。考量到這部分,或許教師加強學生的參與激勵機制,例如採用互動式教學或參與度評分,得以促進學習動機有效提升學生學習成效。第二種模型層面,根據特徵提取可以觀察到MLP這種非線性模型非常適合應用於找尋特徵,其非線性特性使得模型必定會針對每個特徵做出考量,於是我們提出一種假設,是否能應用此特性在模型訓練前找出更加具有訓練價值的模型特徵,後續在利用機器學習去強化特徵方面的訓練
ROC curve數據圖片(從左到右分別是機器學習roc/組合融合roc/MLP模型roc)
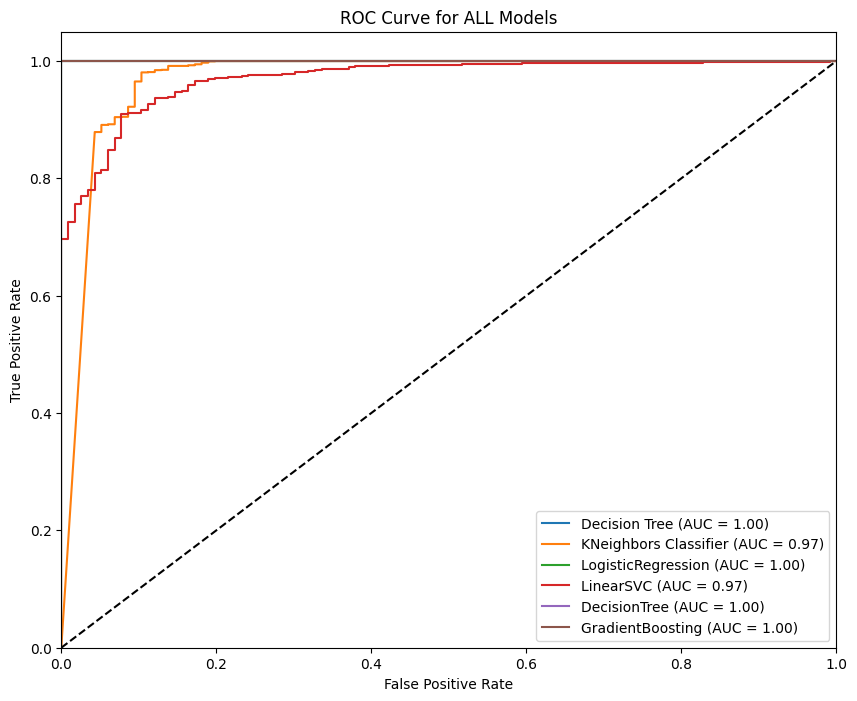
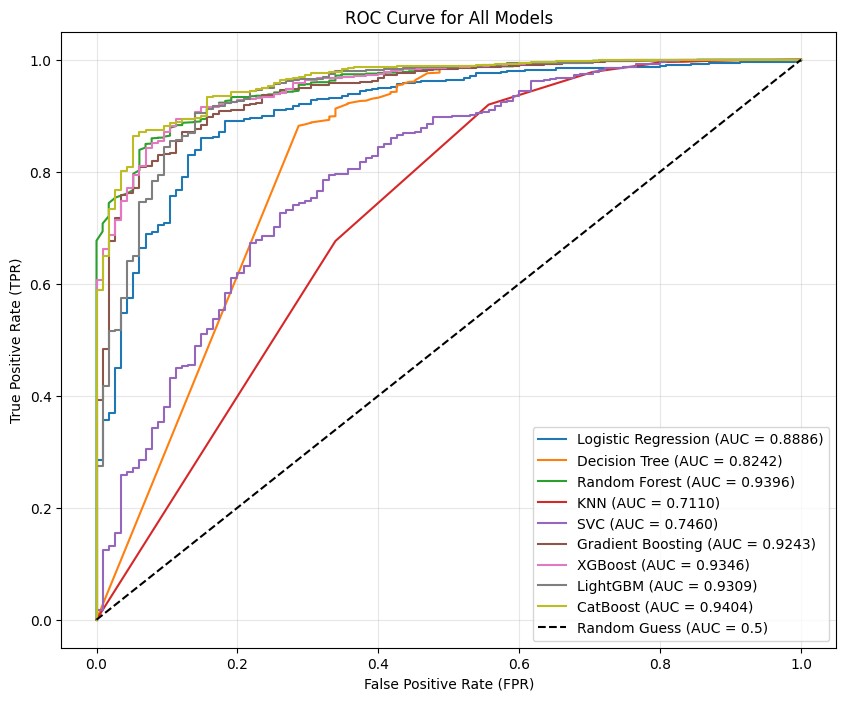
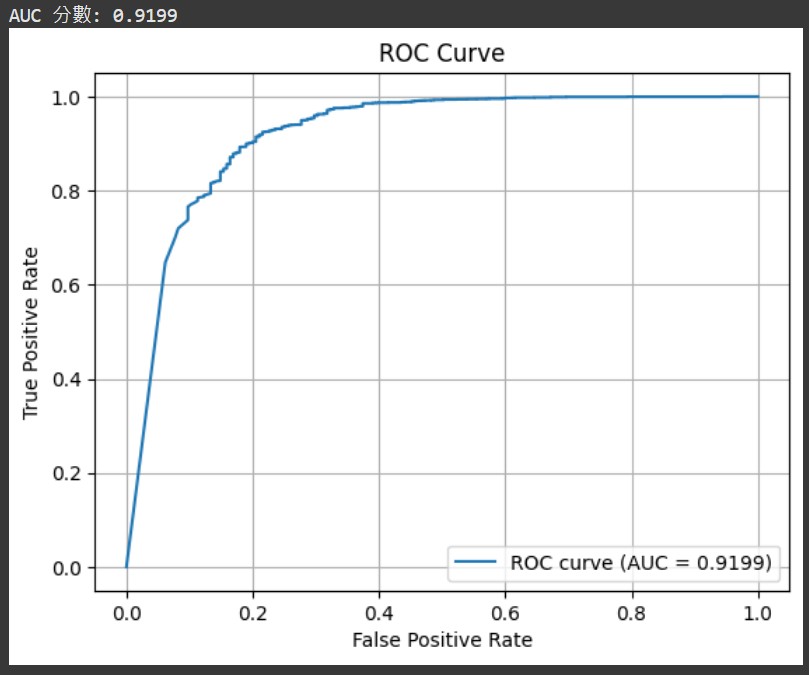
迴歸模型散點圖(R²: 0.6121)
模型特徵分析(左為MLP模型右為機器學習模型)
完整研究海報
點擊以下按鈕查看完整的競賽海報: